This post is less about teaching and more about schadenfreude amusement for you, and catharsis for me. It’s the story of how one unfortunate HTML tag kicked me off almost all search engines and my months-long way back. And why it didn’t matter in the end.
It all started in December 2020: as part of their ongoing cold war with Google, Apple announced that they’re adding Ecosia as a possible default search engine to iOS 14.3. Essentially, it’s a frontend for the Bing search index with the additional benefit of using profits for planting trees.
As one does, the first thing I did was trying to search for my name and…came up empty.
Warily, I checked other search engines: DuckDuckGo1: just my LinkedIn2 and…my RSS feed!? Getting nervous, I went to Bing itself: just some old crap I forgot I have on the page. Suspecting the worst, I went to Yandex who run their own indexer: only my front page (at least!). Finally, I checked my stats and saw that I was only getting traffic from Google and no other search engine.
Now I knew something was very wrong.
Investigation
This webpage exists since 2004 and I’ve never spent much time on search engine optimization (SEO). I try to write good content that I wish existed and therefore gets shared and linked. I also try to have good markup and URLs, but that’s it. Despite not having any notable traffic, I’ve had a slightly increasing stream of visitors over the years, so I didn’t see a reason to spend significant time on it. This changed now if I wanted to find out what’s going on. Thus, I finally opened webmaster accounts at Bing, Yandex, and Google.
The investigation didn’t take very long, because when I tried to check Bing’s index I got this:

Oh.
meBing – and everybody who uses their index – thought that all my URLs were actually just alternate versions of the index page and refused to index them. A quick check over at Yandex confirmed that it was the same problem. Neat!
Turns out, it was entirely my own fault, because every page on my homepage had the following tag:
<link rel="canonical" href="https://hynek.me/" />
Which literally tells the crawlers that the index page is the canonical version of whatever they’re crawling right now.
For some reason it was part of my base template. Why did I put it there? I have no idea! Maybe I used the wrong Hugo variable. Maybe I thought the tag meant something different (specifying my canonical domain?). It came as part of a bigger redesign so my git history was no help either3.
In any case, the damage was done: over time, whenever Bing’s and Yandex’s crawlers came around to check a page for updates, they saw the tag and threw the page out of their index until nothing4 was left.
Undoing the damage
The fix was trivial. I just had to change one line in my base template:
- <link rel="canonical" href="{{ .Site.BaseURL }}" />
+ <link rel="canonical" href="{{ .Permalink }}" />
I did that on December 24th, 2020.
But recovering from the consequences would take much longer than I thought.
While search engines employ automated crawlers to find new content, they also have mechanisms to tell them about new and updated content. Supposedly to send out crawlers manually and not wait for them to notice changes organically – which can take a while.
There are well-known files like sitemap.xml, there are buttons that say “request re-index” and then there’s web APIs and web forms where you can dump lists of URLs that you’d like crawled (again).
None of these actually did anything, except Bing telling me they’ll get right to it. All of these inputs are apparently treated as suggestions at best.
I’ve re-submitted my sitemap with lowered update intervals, extracted the URLs and submitted them for re-indexing, and manually clicked for some URLs5 to please, please, please re-index them. But absolutely nothing happened for weeks.
Maybe my desperate prodding flagged me as a SEO growth hacker. Maybe a canonical tag is a worst-case scenario that radically de-prioritized those pages. In any case, it became a daily routine to check whether Bing already knows that I exist and manually asking it for a re-index of my about page.
I had to wait until January 4th, 2021 for that to happen. Almost two weeks of begging and bargaining. This doesn’t mean that the pages were in the results, though! It took until February until searching for my name on Bing started returning my about page.
It also doesn’t mean that all my pages were re-indexed. In fact, I could watch the pages popping up in “real-time”, as Bing was re-discovering them over the next few months. There’s a handy dashboard that shows you the number of indexed pages:
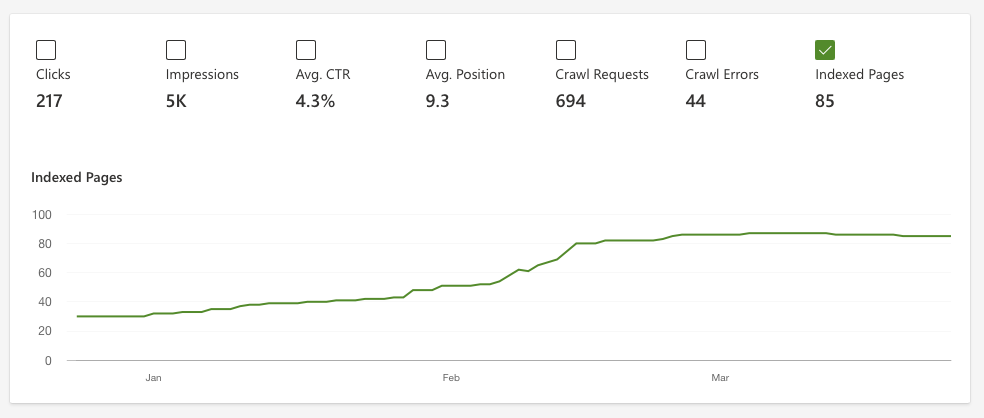
Number of indexed pages over time.
As you can see, despite my prodding it took until March for my whole homepage to be fully indexed again.
So, all in all, it took almost three months to recover from my stupid mistake. Despite having tons of organic, high-quality back links.
What about Google?
I didn’t mention Google above, but it’s kinda their fault why I didn’t notice it any sooner. Even now – after fixing the SEO damage – I’m getting roughly 90% of search traffic from Google. 10% of traffic are nothing if your livelihood doesn’t depend on it and you’re not staring at your analytics all day.
Google simply decided to ignore the tag, because the page was too different from the “canonical” page.
In a way, this reminds me of the browser wars where the “best” browser was the one that could make the most sense of the gibberish HTML everybody was putting on Geocities.
Lessons learned
- If you thought misconfigured DNS takes a long time to fix: think again.
- Google is really good at indexing websites. Even if you inadvertently make it harder for them.
- A lot less (tech-savvy!) people use alternative search engines than you’d think. For this page, DuckDuckGo is 4%, Bing has 2%, Baidu 1.3%. However, 6% is nothing to scoff at if web traffic puts food on your table.
- If you run a website, create a webmaster account at least with Google and Bing, so you learn about such problems immediately. Not like me, years later, by accident. Again, Google is really good at proactively telling you about problems.
Also uses among others the Bing index. ↩︎
For the love of god, unless we know each other, don’t try to add me. I’m not a Pokémon. ↩︎
My private git history may or may not be somewhat less stringent than public projects. ↩︎
“Nothing” is not quite correct. Since my homepage is static and I don’t delete old posts, this meant Bing had indexed all kind of garbage I didn’t even know still existed – complete with its old design. Because these artifacts never got that treacherous tag added. ↩︎
Most notably the about page, so when people search for my name they don’t find random artifacts of mine all over the web, but my own presentation of myself. ↩︎